本文节译自NoSQL Data Modeling Techniques。
NoSQL数据建模中的一般问题
作为前言,首先提出一些NoSQL建模中的一般化问题:
-
与关系建模不同,NoSQL数据建模通常从应用程序查询的角度来建模:
-
关系建模的方式通常是由数据的结构来决定的,设计的主题是:“我能回答什么问题?”
-
NoSQL建模的方式则是由数据访问方式决定(例如要支持哪些查询),设计的主题是:“我能提出什么问题?”
-
-
NoSQL建模通常需要对数据结构和算法有更深的理解。本文中,我们将探讨一些虽然不是针对NoSQL,但是在NoSQL中很实用的数据结构。
-
数据的冗余和反范式化是很重要的。
尽管数据建模技术是没有定式的,但对于特定的系统来说,本文将给出一些思路。
概念性技术
1. 反范式化
反范式化可以被定义为多个文档/表拥有相同的数据副本,以使查询处理变得更简单高效。
2. 聚集
主流的NoSQL数据库均对模式(schema)没有很强的限制:
- Key-Value存储通常不对存储的值有约束,因此值可以是任意的格式。此外,一个业务实体也可以占用多条记录。例如,用户账户可以这样建模:以UserID_name, UserID_email这样的名称作为key。
- 文档型数据库通常则是固有的schema-less。
这样的设计允许实用复杂的内部结构来构建实体,主要包括两方面:
- 最小化一对多的关系(通过嵌套实体),这样,就会减少连接操作。
- 隐藏了异构的业务实体间的不同。
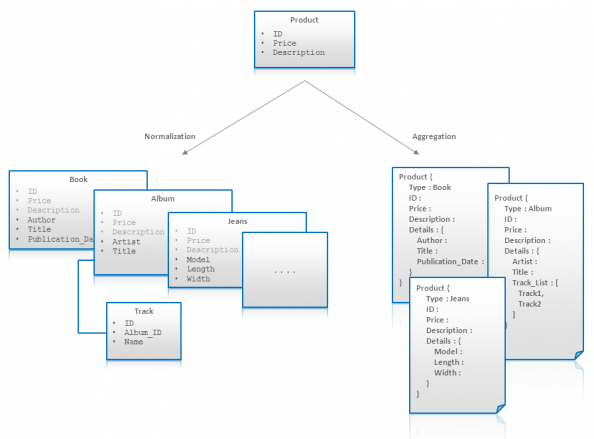
我们可以用如下这张图来展示。这副图对产品实体进行了建模。首先,我们说,所有的产品都有ID,价格和描述。接下来,我们发现不同类型的产品拥有不同的属性,例如书籍的作者和裤子的长度。有些属性是一对多或者多对多的,例如唱片中的曲目等。接下来,我们发现,有些实体难以用固定的属性建模,例如裤子的属性取决于品牌。虽然在关系数据库中,这些模型都是能建出来的,但显然不如NoSQL简洁。
3. 应用程序端连接
NoSQL解决方案中几乎不支持连接。作为“问题驱动”的NoSQL设计,连接通常在设计时就被考虑好了,使用之前描述的反范式化和聚集就可以解决这个问题。当然,有些时候,连接还是无法避免,此时应该由应用程序处理。
一般建模技术
4. 原子聚集
很多NoSQL的解决方案都缺乏对事务的支持。在一些情形中,可以通过使用分布式锁或使用应用程序级别的MVCC来实现事务特性。但通常都是使用上文提到的聚集的特性来保证部分ACID特性。
5. 可枚举键
无序的Key-Value模型有一个很大的优点:数据可以通过对key的hash,分布放在多个服务器上。有序模型更复杂,但有时候有序的键对应用程序来说更有用。考虑下面这个例子:
-
一些NoSQL存储提供原子计数器,可以用来产生ID序列。可以用复合key:userID_messageID存储消息。如果我们知道了最新消息的ID,那么就可以向前遍历所有的消息。
-
也可以利用这样的特性对消息分组,例如按日期分组。
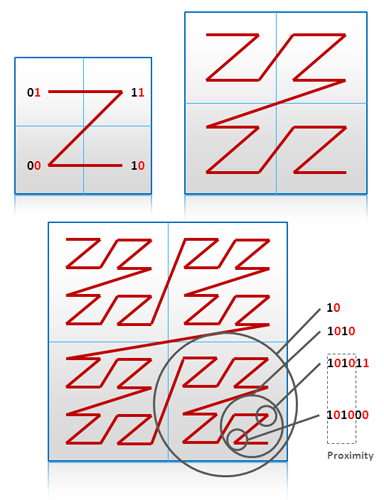
6. 降维
降维是一项把多维数据映射到Key-Value模型或者其他非多维模型的技术。
传统的地理信息系统使用四叉树或者R-树及其变种作为索引。这些结构需要原地更新,并且当数据量很大的时候也会遇到困难。一个方法是,遍历二维的结构,并将其转化为一个一维的列别。这项技术中比较有名的方法叫做Geohash。如下图所示:
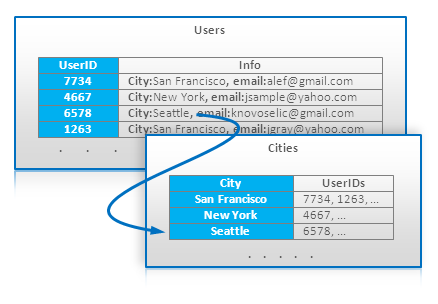
7. 索引表
这项技术主要使用在大表数据库中,看图就好: